
The second half of 2026 has delivered what may be the most intense model release cluster in the history of artificial intelligence. In the span of just a few weeks, OpenAI shipped GPT-5.5 (April 23, 2026), Anthropic followed with Claude Opus 4.8 (May 28, 2026), and Google launched the Gemini 3.5 family (May 19, 2026) during its Google I/O keynote. Each model represents a meaningful step forward from its predecessor. Each company made bold claims about benchmark dominance. And predictably, the internet filled up with hot takes, cherry-picked scores, and breathless YouTube thumbnails.
This article cuts through the noise. Using official benchmark tables, developer testimonials, API pricing data, and real-world workflow analyses, it gives you everything you need to make an informed decision about which model belongs in your stack — whether you are a solo developer, a content team lead, an enterprise architect, or just someone trying to figure out which subscription is worth paying for this month.
The Models at a Glance: What Each One Is and Where It Came From
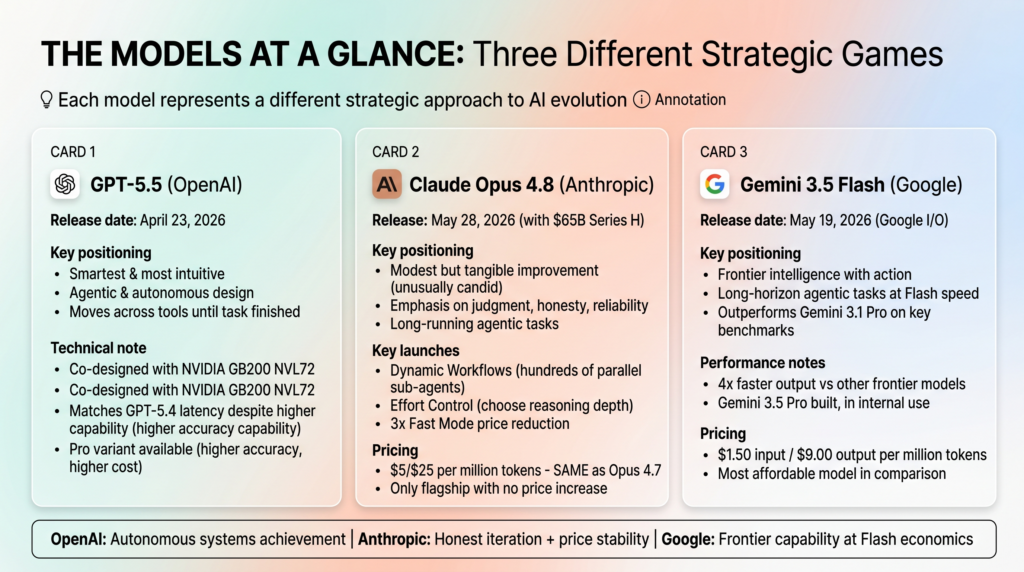
Before diving into benchmarks and use cases, it helps to understand what each model actually represents within its respective ecosystem — because each one is playing a slightly different strategic game.
GPT-5.5 is OpenAI’s “smartest and most intuitive” model to date, released April 23, 2026. OpenAI describes it not just as a smarter version of GPT-5.4, but as a fundamentally different approach to how an AI should work through problems. The framing is agentic and autonomous: GPT-5.5 is designed to understand what you are trying to accomplish holistically, carry the work itself, and “move across tools until a task is finished” without you needing to manage every step. It was co-designed for and trained with NVIDIA GB200 NVL72 systems, and OpenAI engineered it to match GPT-5.4’s per-token latency despite being a significantly more capable model — a non-trivial systems achievement. The model also comes in a “Pro” variant with higher accuracy at substantially higher cost.
Claude Opus 4.8 is Anthropic’s May 28, 2026 upgrade to their flagship Opus line — released the same day as the historic $65 billion Series H funding announcement. Anthropic positions it as “a modest but tangible improvement” over Opus 4.7, which is unusually candid language for a product launch. The emphasis is on judgment, honesty, and reliability in long-running agentic tasks rather than raw benchmark leaps. Key accompanying launches include Dynamic Workflows (running hundreds of parallel sub-agents in Claude Code), Effort Control (letting users choose reasoning depth), and a 3x reduction in Fast Mode pricing. Crucially, Opus 4.8 launches at the same price as Opus 4.7 — $5/$25 per million tokens — making it the only flagship model in this comparison that delivers improvements without a price increase.
Gemini 3.5 Flash is the opening model of Google’s new 3.5 family, launched at Google I/O on May 19, 2026. The key positioning is “frontier intelligence with action” — specifically, the ability to handle complex, long-horizon agentic tasks at the speed traditionally associated with lighter Flash-class models. Google explicitly positioned 3.5 Flash as outperforming Gemini 3.1 Pro on multiple key benchmarks while delivering 4x faster output token generation than other frontier models. Gemini 3.5 Pro is already built and being used internally at Google, with a public rollout expected shortly after this writing. The Flash’s pricing sits at $1.50 input / $9.00 output per million tokens — making it by far the most affordable model in this comparison.
The Benchmark Breakdown: What the Numbers Actually Say
Benchmarks in 2026 are simultaneously more comprehensive and more contentious than ever. Every lab runs its own internal evals alongside public ones, and different scores reflect different conditions, harnesses, and effort levels. What follows is the most complete and honest reading of the available data across all three models.
Coding Performance
Coding benchmarks are the battleground where the 2026 AI race is most clearly fought, and the results here are genuinely interesting because no single model dominates across all evaluations.
On SWE-Bench Verified — the standard benchmark for real-world GitHub issue resolution — Claude Opus 4.8 leads with an impressive 88.60%, followed by GPT-5.5 at 82.60%, with Claude Opus 4.7 at 82.00% and Gemini 3.5 Flash at 78.80% (per Vals AI leaderboard data). This is a meaningful gap: in a benchmark that resists memorization by testing genuine software engineering judgment, Opus 4.8 pulls ahead by six full percentage points over GPT-5.5.
On SWE-Bench Pro — OpenAI’s harder internal variant using real GitHub issues — the picture inverts somewhat. GPT-5.5 scores 58.6% versus Claude Opus 4.7’s 64.3% and Gemini 3.1 Pro’s 54.2%. Note that Opus 4.8 numbers on SWE-Bench Pro were not yet fully published at time of writing given the recency of the release.
On Terminal-Bench 2.0/2.1 — which tests complex command-line workflows requiring planning, iteration, and tool coordination — GPT-5.5 leads at 82.7%, followed by Gemini 3.5 Flash at 76.2% (on Terminal-Bench 2.1), Claude Opus 4.8 at 74.6%, and prior-generation Opus 4.7 at 69.4%. GPT-5.5 has a genuine edge in pure terminal-based autonomous coding that is hard to dismiss.
The most nuanced coding comparison comes from Cursor’s CursorBench evaluation, where Claude Opus 4.8 exceeds prior Opus models across every effort level, with “meaningfully more efficient tool calling, using fewer steps for the same intelligence.” Michael Truell, co-founder of Cursor, specifically called out GPT-5.5 as “noticeably smarter and more persistent than GPT-5.4” — which tells you something about where the competitive bar has landed. Both models are genuinely excellent for professional coding work; the question is which type of coding task you prioritize.
SWE-Bench Verified: Opus 4.8 (88.6%) > GPT-5.5 (82.6%) > Gemini 3.5 Flash (78.8%)
Terminal-Bench: GPT-5.5 (82.7%) > Gemini 3.5 Flash (76.2%) > Opus 4.8 (74.6%)
Reasoning and Academic Performance
On GPQA Diamond — the gold-standard academic reasoning benchmark covering graduate-level science — the three models are essentially tied at the frontier. Claude Opus 4.7 scored 94.2%, Gemini 3.1 Pro 94.3%, and GPT-5.5 93.6%. With Opus 4.8’s improvements over 4.7, it is reasonable to expect Opus 4.8 to match or exceed these figures. This is the benchmark that most clearly shows all three companies have reached a similar frontier on hard academic reasoning — the differentiation is elsewhere.
On Humanity’s Last Exam — arguably the hardest publicly available benchmark — the scores with tools enabled show GPT-5.5 at 52.2%, Opus 4.7 at 54.7%, and Gemini 3.1 Pro at 51.4%. Claude leads here, particularly on the no-tools version where Opus 4.7 scores 46.9% versus GPT-5.5’s 41.4%.
On FrontierMath — which tests advanced mathematical problem solving — GPT-5.5 leads: Tier 1–3 scores of 51.7% versus Gemini 3.1 Pro’s 36.9% and Opus 4.7’s 43.8%. The GPT-5.5 Pro variant pushes to 52.4%. For mathematically intensive work, GPT-5.5 holds a meaningful edge.
Agentic and Professional Work
On GDPval — which measures performance on economically valuable knowledge work across 44 occupations — GPT-5.5 scores 84.9%, Claude Opus 4.7 scores 80.3%, and Gemini 3.1 Pro scores 67.3%. The Gemini number here is notably lower, though the 3.5 Flash results on GDPval-AA show a 1656 Elo score that Google claims surpasses Gemini 3.1 Pro. Even accounting for methodology differences, GPT-5.5 holds the strongest benchmark position for broad professional knowledge work.
On OSWorld-Verified — which measures whether a model can operate real computer environments autonomously — GPT-5.5 scores 78.7% and Claude Opus 4.7 scores 78.0%. The margin is essentially zero; these two are equivalent on computer use. Gemini 3.1 Pro’s numbers weren’t published on this benchmark in comparable conditions.
On MCP Atlas — which tests multi-tool coordination using the Model Context Protocol — Claude Opus 4.7 leads at 79.1%, followed by Gemini 3.1 Pro at 78.2% and GPT-5.5 at 75.3%. For developers building with MCP-based tool orchestration, Claude’s advantage on this benchmark is practically relevant.
On BrowseComp — deep web research requiring multi-step browsing — GPT-5.5 Pro leads at 90.1%, but GPT-5.5 standard (84.4%) is closely matched by Gemini 3.1 Pro (85.9%), with Claude Opus 4.7 at 79.3%.
The OfficeQA Pro benchmark — testing professional document and knowledge work — shows a dramatic gap: GPT-5.5 at 54.1%, Claude Opus 4.7 at 43.6%, Gemini 3.1 Pro at just 18.1%. This is one of GPT-5.5’s most convincing benchmark wins for the practical knowledge work many users actually do day-to-day.
Multimodal and Long Context
On multimodal understanding, Gemini 3.5 Flash leads with 84.2% on CharXiv Reasoning (visual mathematical chart understanding), a reflection of Google’s deep investment in multimodal training. Claude Opus 4.8 features enhanced vision up to 2,576 pixels on the long edge (approximately 3.75 megapixels). GPT-5.5 scores 81.2% on MMMU Pro without tools and 83.2% with tools. For pure image and visual reasoning tasks, Gemini maintains its traditional multimodal edge.
On long-context tasks, Claude demonstrates strong performance: on Graphwalks Parents at 256K tokens, Opus 4.6 scored 93.6% versus GPT-5.5’s 90.1%. At 1 million tokens, Claude again leads at 72.0% versus GPT-5.5’s 58.5%. Claude’s ability to genuinely use its full context window — not just claim a large context window — is one of its most consistently documented real-world advantages.
Pricing: The Numbers That Actually Determine Your Decision

Benchmark scores only matter in the context of what you are paying for them. The pricing spread between these three models is substantial, and in some cases it dramatically changes the calculus of which model makes sense for a given use case.
GPT-5.5 via the OpenAI API costs $5.00 per million input tokens and $30.00 per million output tokens. Cached input is available at $0.50 per million tokens. The Pro variant escalates significantly to $30.00 input / $180.00 output per million tokens — a pricing tier for genuinely demanding, high-accuracy applications. Batch and Flex pricing are available at half the standard rate, while Priority processing runs at 2.5x. The context window is 1 million tokens.
Claude Opus 4.8 via the Anthropic API costs $5.00 per million input tokens and $25.00 per million output tokens — $5 cheaper per million output tokens than GPT-5.5. Fast Mode (which delivers 2.5x the speed) is priced at $10 input / $50 output per million tokens, and notably Anthropic reduced Fast Mode pricing by 3x compared to previous Opus models at this launch. The context window extends to 200,000 tokens with support for up to 300,000 output tokens on select models. Prompt caching is available to reduce costs on repeated context.
Gemini 3.5 Flash via the Google AI API costs $1.50 per million input tokens and $9.00 per million output tokens. This makes it roughly 3.3x cheaper on input and 3.3x cheaper on output than both Opus 4.8 and GPT-5.5. The context window is 1 million tokens with up to 65,000 output tokens. For high-volume applications where cost efficiency matters as much as raw capability, Gemini 3.5 Flash occupies a genuinely different price point.
Input Cost: Gemini 3.5 Flash ($1.50) << Claude Opus 4.8 ($5.00) = GPT-5.5 ($5.00)
Output Cost: Gemini 3.5 Flash ($9.00) << Claude Opus 4.8 ($25.00) < GPT-5.5 ($30.00)
The cost structure matters most when you are running agentic pipelines, high-volume API calls, or enterprise applications where token consumption scales with business volume. At $1.50/$9.00 per million tokens, Gemini 3.5 Flash is a fundamentally different conversation for infrastructure budgeting than either of its competitors.
Head-to-Head: Specific Use Cases Broken Down
For Agentic Coding and Software Engineering
The most nuanced real-world picture comes from developers who have actually used all three models in production coding contexts. The consensus emerging from sources like Composio, MindStudio, and Cursor is that GPT-5.5 and Claude Opus 4.8 are the two serious choices, with the decision coming down to what kind of coding work dominates your use case.
GPT-5.5 is generally described as better for rapid, autonomous workflows where speed and broad system comprehension matter — “holding context across large systems, reasoning through ambiguous failures, checking assumptions with tools, and carrying changes through the surrounding codebase,” as OpenAI’s announcement puts it. The Terminal-Bench scores bear this out. Early testers at NVIDIA described using it like “having a limb amputated” when access was revoked.
Claude Opus 4.8, on the other hand, has carved out a specific reputation for high-stakes autonomous workflows where errors are costly. The critical differentiator that Anthropic’s announcement emphasizes — and that early testers across Sourcegraph, Devin, Cursor, and others have corroborated — is that Opus 4.8 is four times less likely than its predecessor to allow flaws in code to pass unremarked. It flags uncertainties, catches its own mistakes, pushes back when a plan isn’t sound, and builds up confidence before making big changes. For code that ships to production, this calibration matters more than raw task completion rate.
Gemini 3.5 Flash is a strong third option for high-volume, cost-sensitive coding pipelines where you need frontier-quality results at Flash-tier pricing. Its Terminal-Bench 2.1 score of 76.2% surpasses prior-generation Gemini Pro models and approaches the top two. For applications generating large amounts of code with high token volume — codegen pipelines, automated documentation, code translation — the 3.3x cost advantage over Opus 4.8 is highly relevant.
For Long-Horizon Agentic Tasks
One of the most revealing third-party evaluations comes from an undisclosed company’s Super-Agent benchmark, reported in Anthropic’s launch post: Claude Opus 4.8 was the only model to complete every case end-to-end, beating prior Opus models and GPT-5.5 at parity on cost. The benchmark covered agent products in translation, deep research, slide-building, and analysis. Claude Code’s new Dynamic Workflows feature — which can plan and run hundreds of parallel sub-agents in a single session — is Opus 4.8’s most powerful capability for long-horizon autonomous work, and no comparable orchestration system exists at this level for GPT-5.5 or Gemini 3.5 in their current forms.
Gemini 3.5 Flash’s Antigravity harness enables comparable multi-agent orchestration from Google’s side, and Google showcased impressive demos: synthesizing the AlphaZero paper and coding a fully playable game in six hours, transforming legacy codebases to Next.js, and parallel sub-agent workflows for enterprise data management. For enterprises already in the Google Cloud ecosystem, this is a compelling native capability.
For Creative Writing and Content Work
This is an area where benchmark scores are largely irrelevant — what matters is the lived experience of using the model as a creative partner. The user base and developer community tell a consistent story here: Claude Opus 4.8 leads for long-form creative and professional writing tasks. An early tester quoted in Anthropic’s announcement described Opus 4.8 as “faster, easier to collaborate with, and better at carrying context and style direction across a long session,” and specifically noted it as “the model I kept trusting for work where voice, taste, and technical execution all have to happen side-by-side.”
This reputation for tonal consistency, stylistic fidelity, and natural prose quality is not new for Claude — it has been the dominant perception among professional writers for two model generations. Opus 4.8’s improvements in honesty and uncertainty calibration are also directly relevant for content creators who rely on Claude to flag when it’s unsure, rather than generating confident-sounding misinformation.
GPT-5.5 performs strongly on structured professional writing (GPT-5.5 Pro scored significantly better than GPT-5.4 Pro on “business, legal, education, and data science” writing tasks), and its OfficeQA Pro score of 54.1% versus Gemini’s 18.1% suggests a meaningful edge in document-heavy professional writing tasks. For business writing, reports, and structured documents, GPT-5.5 is highly competitive.
Gemini 3.5 Flash’s creative writing capability is harder to assess from official benchmarks, but its richer multimodal generation capabilities — generating interactive web UIs from descriptions, creating visual branding concepts, building interactive animations for research papers — make it the strongest of the three for multimodal creative work that combines text with visual or interactive output.
For Research and Scientific Work
GPT-5.5’s performance on scientific benchmarks is notable. On GeneBench (multi-stage genetic and quantitative biology analysis), GPT-5.5 scores 25.0% (with the Pro variant at 33.2%), comparing favorably to the field. On BixBench (bioinformatics and data analysis), it achieved “leading performance among models with published scores.” An immunology professor used GPT-5.5 Pro to analyze a gene-expression dataset with 62 samples and 28,000 genes, producing a detailed research report that “would have taken his team months.” A mathematically-inclined early access user used it to help discover a new proof about Ramsey numbers, later verified in Lean.
Claude Opus 4.8 scores 46.9% on Humanity’s Last Exam without tools (versus GPT-5.5’s 41.4%), suggesting strong deep reasoning on hard academic problems. Its long-context advantage means it can hold entire research papers, datasets, and prior session context simultaneously in a way that is genuinely useful for sustained research work.
For Enterprise and Legal Use Cases
Claude Opus 4.8 stands out strongly here. On the Legal Agent Benchmark, it delivered the highest score recorded and became “the first model to break 10% overall on the all-pass standard” — a threshold described as translating “directly into how much real attorney work our customers can hand off with confidence.” On GDPval-AA for economically valuable knowledge work, Gemini 3.5 Flash’s 1,656 Elo represents strong performance, while GPT-5.5’s 84.9% win rate across 44 occupations makes it broadly capable for enterprise knowledge work.
The enterprise ecosystem integrations matter here too. Claude is the only frontier model available on all three major cloud platforms — AWS Bedrock, Google Cloud Vertex AI, and Microsoft Azure Foundry simultaneously. GPT-5.5 is available via Azure and OpenAI’s own API but not natively on Google Cloud. Gemini 3.5 is natively available on Google Cloud and via the Gemini API. For enterprises with existing cloud contracts and data sovereignty requirements, this availability matrix can determine the decision before a single benchmark is consulted.
Safety, Alignment, and Trust: The Dimension That Benchmarks Miss

This comparison would be incomplete without addressing one of the most consequential differentiators between these three labs: their approach to safety, alignment, and the use policies that govern what their models will and will not do.
Claude Opus 4.8 was released with a full alignment assessment from Anthropic’s Alignment team. The findings reported in the system card are significant: Opus 4.8 reaches “new highs on measures of prosocial traits like supporting user autonomy and acting in the user’s best interest,” while showing “rates of misaligned behavior (such as deception or cooperation with misuse) that are substantially lower than Opus 4.7, and similar to our best-aligned model, Claude Mythos Preview.” The honesty improvements — 4x less likely to allow code flaws to pass unremarked — are a safety property as much as a capability one. Anthropic’s refusal to remove contractual prohibitions on surveillance and autonomous weapons use, even at the cost of federal contracts, is a tangible demonstration of where these values sit relative to commercial pressure.
GPT-5.5 includes OpenAI’s “strongest set of safeguards to date” and rates the model as “High” (not Critical) under its Preparedness Framework for cybersecurity capabilities, with new targeted classifiers for potential cyber risk. OpenAI’s approach is characterized by layered safeguards combined with expanded access programs — the Trusted Access for Cyber initiative specifically enables verified security professionals to use GPT-5.5’s cybersecurity capabilities with fewer restrictions for legitimate defensive work.
Gemini 3.5 was developed in accordance with Google’s Frontier Safety Framework, with “strengthened cyber and CBRN safeguards,” and notably uses interpretability tools “that help check and understand the AI’s inner reasoning before it provides a response” — a technical approach to transparency that is methodologically distinct from the other two labs.
All three labs are operating responsibly at the frontier. The differences are philosophical and structural: Anthropic prioritizes alignment measurement and constitutional principles, OpenAI prioritizes scaled safeguards with trusted access tiers, and Google is investing in technical interpretability. For enterprise buyers making procurement decisions, these are worth understanding in depth before signing agreements.
The Pricing vs. Performance Verdict: Who Should Use What
Rather than declaring a single winner — which would be intellectually dishonest given how genuinely differentiated these models are — here is a clear decision framework built from everything above.
Choose GPT-5.5 if: your primary workload involves autonomous computer use, terminal-based coding workflows, professional knowledge work at scale (especially OfficeQA-style tasks), advanced mathematics, or scientific research where you need a model that can function as a genuine “co-scientist.” GPT-5.5’s combination of Terminal-Bench leadership, GDPval scores, and OSWorld performance makes it the strongest all-around agentic agent for broad professional work. The $5/$30 pricing is identical to Opus 4.8 on input but $5 more per million output tokens, which is relevant at high volume.
Choose Claude Opus 4.8 if: your work involves high-stakes agentic workflows where errors are costly, long-form creative and professional writing, sustained multi-turn collaborative sessions, legal or compliance-sensitive applications, MCP-based tool orchestration, or any context where you need a model that genuinely flags its own uncertainties rather than pushing forward confidently. Opus 4.8’s SWE-Bench Verified lead, long-context performance, alignment properties, and reputation among professional writers make it the best choice for quality-first use cases. Its $5/$25 pricing is the most competitive at the frontier tier, and the 3x reduction in Fast Mode pricing makes high-volume agentic work more accessible than it was with Opus 4.7.
Choose Gemini 3.5 Flash if: you are building high-volume applications or pipelines where cost efficiency matters as much as frontier capability, you are working in multimodal contexts (especially visual reasoning and interactive UI generation), you are inside the Google Cloud ecosystem, or you need a model that delivers near-flagship performance at 4x the output speed of competitors. At $1.50/$9.00, it is the most financially accessible frontier-class model, and its Antigravity multi-agent harness makes it a serious option for large-scale agentic deployments. Gemini 3.5 Pro (imminent) will likely push capability further and directly challenge Opus 4.8 and GPT-5.5 at the top tier.
The Bigger Picture: What This Three-Way Race Means
The fact that GPT-5.5, Claude Opus 4.8, and Gemini 3.5 are all competitive at the frontier simultaneously — with no model dominating every benchmark by a wide margin — represents a fundamentally new state of the AI industry. For the first years of the frontier AI era, the question was who was ahead. In mid-2026, the honest answer is that all three are at the frontier, and the differentiation is about style of intelligence, type of task, and ecosystem alignment as much as raw capability.
GPT-5.5 is a model that wants to do the work for you — take the messy task, figure out the steps, use the tools, and come back with a finished product. Claude Opus 4.8 is a model that wants to work with you — collaborate, flag uncertainties, ask the right questions, and build confidence before taking big actions. Gemini 3.5 Flash wants to scale across your ecosystem — integrate with everything Google, run fast at low cost, and power the kind of multi-agent orchestration that large enterprises and consumer products need at volume.
None of those orientations is objectively superior. They reflect different philosophies about what powerful AI should be. The good news for developers and businesses in 2026 is that for the first time, you can genuinely choose the orientation that fits your work — rather than simply choosing whoever released the most capable model this month.
The race is no longer just about benchmark scores. It is about which company’s vision of how humans and AI should work together most closely aligns with yours.
FAQs
The best model depends on your use case. GPT-5.5 leads in coding and general reasoning, Claude Opus 4.8 excels at long-form writing and nuanced analysis, while Gemini 3.5 dominates multimodal tasks and real-time web integration.
Claude Opus 4.8 generally outperforms GPT-5.5 in creative writing tasks, producing more nuanced, stylistically varied, and contextually rich content. GPT-5.5 remains competitive but tends toward more structured, predictable outputs.
Gemini 3.5 is a strong competitor for everyday tasks, especially if you rely heavily on Google Workspace integration or need real-time search capabilities. However, GPT-5.5 still holds an edge in pure reasoning and complex instruction-following scenarios.
Claude Opus 4.8 actually offers a larger effective context window and maintains better recall across extremely long documents compared to GPT-5.5. This makes it the preferred choice for analyzing lengthy reports, legal documents, or entire codebases.
Claude Opus 4.8 is widely preferred for business use cases requiring careful, accurate, and safety-conscious outputs, such as legal, financial, or compliance-related tasks. Gemini 3.5 is better suited for businesses already embedded in the Google ecosystem needing fast, multimodal, data-connected workflows.





